Multi-Threaded PPPoE using XDP
After years of waiting and annoying our landlord (which I don't think helped at all), we finally got an internet upgrade in the form of Fiber To The Home (FTTH) that catapults us straight to the 21st century.
More interestingly, our local Munich internet provider (M-Net) was able to offer speeds of up to 5 Gbit/s download (2.5 Gbit/s upload) over XGS-PON. That's quite impressive and the option I went with to finally replace that legacy Deutsche Telekom "Supervectoring" connection.
The M-Net technicians, installing the equipment at my place (again thanks much & great job), ran an initial speed test over TCP and got extremely close to the 5 Gbit/s speeds using their custom equipment. However, I
- spotted they weren't squeezing everything out of line MTU
- know from reading their forum, M-Net likes to slightly overprovision
so I did the standard thing when getting new internet... Run all the Speedtests!
Hardware
I've been using my custom DSL modems and routers for years now, so here's a little summary of the equipment I'm using for this project:
- FS.com XGS-PON ONT SKU:185594
- Protectli VP6670 with
- Intel Core i7-1255U
- Intel x710 SFP+ NIC with the XGS-PON ONT plugged into it
The Protectli is running a Debian Trixie VM that serves as a router + running nftables firewall with:
- 8 CPU cores
- 4 GB of memory
Initial Tests
... have been pretty "underwhelming".
A bit of a first-world complaint, to be honest, considering most internet services in Germany don't even come close to 1 Gbit/s download speeds.
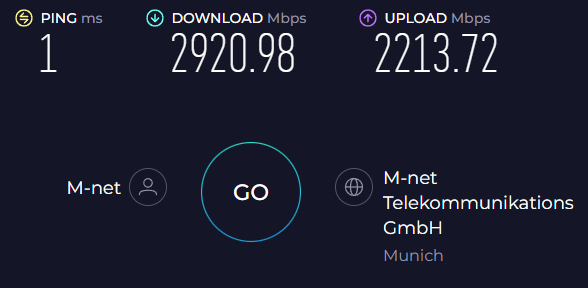
So I ran a first set of "low-hanging-fruit"-optimizations that I never had to execute on that previous 250 Mbit/s DSL line to see if that'd improve speeds. Since I am running in a Virtual Environment - Proxmox in particular - the obvious things to do are:
- Make sure to use "Host" CPU type for the VM, so it can benefit from all hardware optimizations
- PCI Passthrough for the Intel x710 NIC, so we skip network virtualization (/ virtio)
Which did improve speed by quite a bit
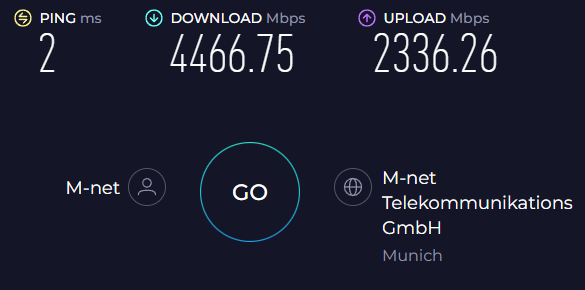
That's when I started looking at the load of my router VM ...
Receive Side Scaling
Running those Speedtests, I noticed something interesting when putting that fiber under pressure:
Tasks: 174 total, 3 running, 171 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 2.0 us, 0.0 sy, 0.0 ni, 98.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu2 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu3 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu4 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu5 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu6 : 0.0 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi,100.0 si, 0.0 st
%Cpu7 : 2.0 us, 0.0 sy, 0.0 ni, 98.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 3920.2 total, 3177.8 free, 532.6 used, 424.6 buff/cache
MiB Swap: 980.0 total, 980.0 free, 0.0 used. 3387.6 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
57 root 20 0 0 0 0 R 94.1 0.0 2:12.61 ksoftirqd/6
From this output we can see Core #6 is a bit struggling under an interrupt flood. Even more interesting, it's always CPU #6.
NICs are typically designed to distribute incoming traffic across multiple CPU cores by placing packets into different receive queues. This helps ensure that packet processing is "load-balanced" across available compute cores. A process called Receive Side Scaling (RSS).
The way how a NIC puts packets into receive queues is by using a hash function on packet data. What goes into that hash depends on the NIC's implementation, but typically it's something like Source & Destination IPs and Ports to guarantee packets for the same "flow" are processed by the same core. Summarized, the NIC has to have some protocol specific knowledge.
So why aren't my packets load-balanced across all CPU cores?
Because
- even in 2025 - we still like to use stuff like PPPoE. A protocol that adds a bit of additional overhead to our precious packets between L2 (Ethernet / VLAN) and L3 (IP) headers.
- NICs need to be smart enough / support PPPoE when using RSS and my NIC obviously doesn't
What can we do about it? A couple of solutions come to mind:
- Buy a new NIC that understands PPPoE
- Use a different PPPoE implementation (accel-ppp an implementation used in VyOS seems to be the obvious choice)
- Look into Intel's Dynamic Device Personalization (DPP) feature, which allows you to configure NICs on-the-fly
- eXpress Data Path (XDP) cpumap's
XDP Implementation
Because I am quite used to BPF and XDP, I decided to give the last option a try. In a nutshell:
- XDP allows us to process packets in the NIC's receive path, before they are passed to the kernel
- Using a
BPF_MAP_TYPE_CPUMAPandbpf_redirect_mapwe can redirect frames to different CPU cores
The following program:
- Checks if we are dealing with a VLAN-tagged PPPoE packet
- Extracts IPv4 or IPv6 source and destination addresses from a packet
- Extracts TCP or UDP source and destination ports from a packet
- Calculates a CRC32 "hash" based on this 4-tuple
- Calculates a CPU index by using a modulo on the hash and the number of CPU cores available
There are a couple of comments in the code that explain what's going on. Also I should note that NICs typically use a Toeplitz function to calculate the hash. I am abusing a simpler CRC function here, which is giving me good enough results.
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_endian.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/in.h>
#include <linux/ipv6.h>
#include <linux/tcp.h>
#include <linux/udp.h>
// Defines number of CPUs in the system. This can be set to a lower value than
// available CPUs
#define MAX_CPU 8
#define PPPOE_P_IP 0x0021
#define PPPOE_P_IPV6 0x0057
#define IP_TCP 0x06
#define IP_UDP 0x11
struct {
__uint(type, BPF_MAP_TYPE_CPUMAP);
__uint(max_entries, MAX_CPU);
__uint(key_size, sizeof(int));
__uint(value_size, sizeof(int));
} cpu_map SEC(".maps");
typedef struct vlan_hdr {
__be16 h_vlan_TCI;
__be16 h_vlan_encapsulated_proto;
} vlan_hdr;
typedef struct pppoe_hdr {
__u8 version : 4;
__u8 type : 4;
__u8 code;
__u16 session_id;
__u16 length;
__u16 protocol;
} pppoe_hdr;
typedef struct __attribute__((packed)) tuple {
__u32 saddr;
__u32 daddr;
__u16 sport;
__u16 dport;
__u8 proto;
__u16 header_len;
} tuple;
// Calculates CRC "hash" for the flow
static __always_inline __u32 crc32(const void *data, __u64 len) {
const unsigned char *p = data;
__u32 crc = 0xFFFFFFFF;
for (__u64 i = 0; i < len; i++) {
crc ^= p[i];
for (int j = 0; j < 8; j++) {
if (crc & 1)
crc = (crc >> 1) ^ 0xEDB88320;
else
crc = crc >> 1;
}
}
return ~crc;
}
// Calculates XDP data offsets and handles out of bounds check
__always_inline void *__offset(void *start, void *end, __u32 offset, __u32 len) {
void *ptr = start + offset;
if (ptr + len > end) {
return NULL;
}
return ptr;
}
// Extracts IPv4 L3 information for the hash
__always_inline int __ipv4(void *data, void *data_end, tuple *tuple) {
struct iphdr *ip;
if (ip = __offset(data, data_end, 0, sizeof(struct iphdr)), ip == NULL) {
return -1;
}
tuple->saddr = ip->saddr;
tuple->daddr = ip->daddr;
tuple->proto = ip->protocol;
tuple->header_len = ip->ihl * 4;
return 0;
}
// Extracts IPv6 L3 information for the hash, by folding v6 addresses into
// 32-bit values
__always_inline int __ipv6(void *data, void *data_end, tuple *tuple) {
struct ipv6hdr *ip;
int *saddr_ptr;
int *daddr_ptr;
if (ip = __offset(data, data_end, 0, sizeof(struct ipv6hdr)), ip == NULL) {
return -1;
}
saddr_ptr = (int *)&ip->saddr.in6_u.u6_addr32;
tuple->saddr ^= saddr_ptr[0];
tuple->saddr ^= saddr_ptr[1];
tuple->saddr ^= saddr_ptr[2];
tuple->saddr ^= saddr_ptr[3];
daddr_ptr = (int *)&ip->daddr.in6_u.u6_addr32;
tuple->daddr ^= daddr_ptr[0];
tuple->daddr ^= daddr_ptr[1];
tuple->daddr ^= daddr_ptr[2];
tuple->daddr ^= daddr_ptr[3];
tuple->header_len = sizeof(struct ipv6hdr);
tuple->proto = ip->nexthdr;
return 0;
}
// Extracts TCP L4 information for the hash
__always_inline int __tcp(void *data, void *data_end, tuple *tuple) {
struct tcphdr *tcp;
if (tcp = __offset(data, data_end, 0, sizeof(struct tcphdr)), tcp == NULL) {
return -1;
}
tuple->sport = tcp->source;
tuple->dport = tcp->dest;
return 0;
}
// Extracts UDP L4 information for the hash
__always_inline int __udp(void *data, void *data_end, tuple *tuple) {
struct udphdr *udp;
if (udp = __offset(data, data_end, 0, sizeof(struct udphdr)), udp == NULL) {
return -1;
}
tuple->sport = udp->source;
tuple->dport = udp->dest;
return 0;
}
SEC("xdp") int start(struct xdp_md *ctx) {
struct ethhdr *eth;
vlan_hdr *vlan;
pppoe_hdr *pppoe;
tuple tuple;
void *data_end;
void *data;
data = (void *)(long)ctx->data;
data_end = (void *)(long)ctx->data_end;
// Make sure tuple is all zero
__builtin_memset(&tuple, 0, sizeof(tuple));
// Get pointer to ethernet header
if (eth = __offset(data, data_end, 0, sizeof(struct ethhdr)), eth == NULL) {
return XDP_PASS;
}
// We only support VLAN-tagged packets
if (bpf_ntohs(eth->h_proto) != ETH_P_8021Q) {
return XDP_PASS;
}
// Get pointer to VLAN header
if (vlan = __offset(eth, data_end, sizeof(struct ethhdr), sizeof(vlan_hdr)), vlan == NULL) {
return XDP_PASS;
}
// We only care about PPP Session data
if (bpf_ntohs(vlan->h_vlan_encapsulated_proto) != ETH_P_PPP_SES) {
return XDP_PASS;
}
// Get pointer to PPPoE header
if (pppoe = __offset(vlan, data_end, sizeof(vlan_hdr), sizeof(pppoe_hdr)), pppoe == NULL) {
return XDP_PASS;
}
// We only support IPv4 and IPv6 packets
if (bpf_ntohs(pppoe->protocol) != PPPOE_P_IP &&
bpf_ntohs(pppoe->protocol) != PPPOE_P_IPV6) {
return XDP_PASS;
}
// Extract L3 data for the hash
switch (bpf_ntohs(pppoe->protocol)) {
case PPPOE_P_IP:
if (__ipv4((void *)pppoe + sizeof(pppoe_hdr), data_end, &tuple) < 0) {
return XDP_PASS;
}
break;
case PPPOE_P_IPV6:
if (__ipv6((void *)pppoe + sizeof(pppoe_hdr), data_end, &tuple) < 0) {
return XDP_PASS;
}
break;
}
// We only support TCP and UDP packets
if (tuple.proto != IPPROTO_TCP && tuple.proto != IPPROTO_UDP) {
return XDP_PASS;
}
void *proto_start = (void *)pppoe + sizeof(pppoe_hdr) + tuple.header_len;
switch (tuple.proto) {
case IPPROTO_TCP:
if (__tcp(proto_start, data_end, &tuple) < 0) {
return XDP_PASS;
}
break;
case IPPROTO_UDP:
if (__udp(proto_start, data_end, &tuple) < 0) {
return XDP_PASS;
}
break;
}
// Calculate CPU for the packet
__u32 cpu = crc32(&tuple, 12) % MAX_CPU;
return bpf_redirect_map(&cpu_map, cpu, 0);
}
char LICENSE[] SEC("license") = "GPL";
Let's compile this thing:
$ clang -O2 -g -target bpf -D__TARGET_ARCH_x86 -c ppp-xdp-kern.c -o ppp-xdp-kern.o
Load it into the kernel (My NIC is called enp1s0f0):
$ ip link set dev enp1s0f0 xdpdrv object ppp-xdp-kern.o sec xdp
And populate all entries in the cpumap (again 8 cores in my case). The value for each key is of type bpf_cpumap_val,
which is a 32-bit unsigned integer specifying a queue size.
$ bpftool map update name cpu_map key 0x00 0x00 0x00 0x00 value 0x00 0x40 0x00 0x00
$ bpftool map update name cpu_map key 0x01 0x00 0x00 0x00 value 0x00 0x40 0x00 0x00
$ bpftool map update name cpu_map key 0x02 0x00 0x00 0x00 value 0x00 0x40 0x00 0x00
$ bpftool map update name cpu_map key 0x03 0x00 0x00 0x00 value 0x00 0x40 0x00 0x00
$ bpftool map update name cpu_map key 0x04 0x00 0x00 0x00 value 0x00 0x40 0x00 0x00
$ bpftool map update name cpu_map key 0x05 0x00 0x00 0x00 value 0x00 0x40 0x00 0x00
$ bpftool map update name cpu_map key 0x06 0x00 0x00 0x00 value 0x00 0x40 0x00 0x00
$ bpftool map update name cpu_map key 0x07 0x00 0x00 0x00 value 0x00 0x40 0x00 0x00
Time for a final Speedtest, that shows great success.
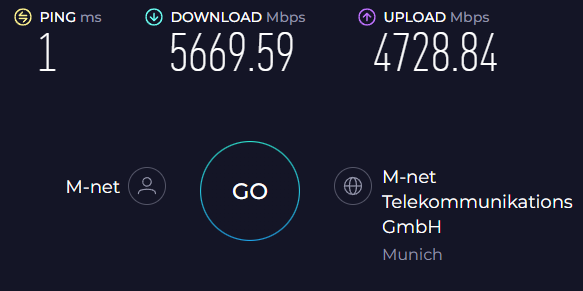
Another look at top confirms we are indeed load-balancing packets across multiple cores & the cpumap is working as
expected:
Tasks: 179 total, 1 running, 178 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.0 us, 2.0 sy, 0.0 ni, 85.7 id, 0.0 wa, 0.0 hi, 12.2 si, 0.0 st
%Cpu1 : 0.0 us, 2.0 sy, 0.0 ni, 94.0 id, 0.0 wa, 0.0 hi, 4.0 si, 0.0 st
%Cpu2 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu3 : 0.0 us, 0.0 sy, 0.0 ni, 96.1 id, 0.0 wa, 0.0 hi, 3.9 si, 0.0 st
%Cpu4 : 0.0 us, 0.0 sy, 0.0 ni, 98.0 id, 0.0 wa, 0.0 hi, 2.0 si, 0.0 st
%Cpu5 : 0.0 us, 0.0 sy, 0.0 ni, 86.0 id, 0.0 wa, 0.0 hi, 14.0 si, 0.0 st
%Cpu6 : 0.0 us, 0.0 sy, 0.0 ni, 93.8 id, 0.0 wa, 0.0 hi, 6.2 si, 0.0 st
%Cpu7 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 3920.2 total, 3159.1 free, 550.0 used, 425.8 buff/cache
MiB Swap: 980.0 total, 980.0 free, 0.0 used. 3370.2 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
46141 root 20 0 0 0 0 S 16.0 0.0 0:01.34 cpumap/0/map:300
46151 root 20 0 0 0 0 S 14.0 0.0 0:00.67 cpumap/5/map:300
46143 root 20 0 0 0 0 S 6.0 0.0 0:00.29 cpumap/1/map:300
46153 root 20 0 0 0 0 S 6.0 0.0 0:01.79 cpumap/6/map:300
46145 root 20 0 0 0 0 S 4.0 0.0 0:00.45 cpumap/2/map:300
46147 root 20 0 0 0 0 S 2.0 0.0 0:00.40 cpumap/3/map:300
46149 root 20 0 0 0 0 S 2.0 0.0 0:01.01 cpumap/4/map:300
As mentioned, there's likely more room for improvement using a proper hash function here which is a project for another weekend.