Intro
This is a non-scientific collection of personal learnings. There's no guarantee you'll experience a constant level of entertainment on this website, because topics will be wildly mixed.
I do quite a bit of networking, run AS208549, play around with eBPF and optical fiber. Lately I am trying to get a better understanding of Cortex-M microcontrollers and ARM assembly. There's also a bit of stuff on my dusty GitHub profile.
MUC statistics
Many moons ago I set up an ADS-B receiver to track flights at MUC, which still seems to work fine...
There's more details on my Plane-Spotting website, but here's how many planes landed in MUC today.
Christian Ehrig - Munich (2025)
Braindumps
2025-10-16: Multi-Threaded PPPoE using XDP
2025-03-30 AI telephone agent using Asterisk and Cloudflare Workers AI
2025-03-13: STM32F439 openocd ITM Debugger
Multi-Threaded PPPoE using XDP
After years of waiting and annoying our landlord (which I don't think helped at all), we finally got an internet upgrade in the form of Fiber To The Home (FTTH) that catapults us straight to the 21st century.
More interestingly, our local Munich internet provider (M-Net) was able to offer speeds of up to 5 Gbit/s download (2.5 Gbit/s upload) over XGS-PON. That's quite impressive and the option I went with to finally replace that legacy Deutsche Telekom "Supervectoring" connection.
The M-Net technicians, installing the equipment at my place (again thanks much & great job), ran an initial speed test over TCP and got extremely close to the 5 Gbit/s speeds using their custom equipment. However, I
- spotted they weren't squeezing everything out of line MTU
- know from reading their forum, M-Net likes to slightly overprovision
so I did the standard thing when getting new internet... Run all the Speedtests!
Hardware
I've been using my custom DSL modems and routers for years now, so here's a little summary of the equipment I'm using for this project:
- FS.com XGS-PON ONT SKU:185594
- Protectli VP6670 with
- Intel Core i7-1255U
- Intel x710 SFP+ NIC with the XGS-PON ONT plugged into it
The Protectli is running a Debian Trixie VM that serves as a router + running nftables firewall with:
- 8 CPU cores
- 4 GB of memory
Initial Tests
... have been pretty "underwhelming".
A bit of a first-world complaint, to be honest, considering most internet services in Germany don't even come close to 1 Gbit/s download speeds.
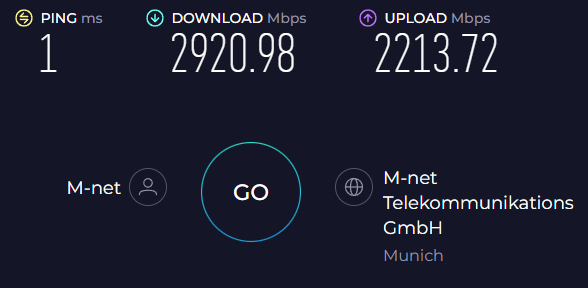
So I ran a first set of "low-hanging-fruit"-optimizations that I never had to execute on that previous 250 Mbit/s DSL line to see if that'd improve speeds. Since I am running in a Virtual Environment - Proxmox in particular - the obvious things to do are:
- Make sure to use "Host" CPU type for the VM, so it can benefit from all hardware optimizations
- PCI Passthrough for the Intel x710 NIC, so we skip network virtualization (/ virtio)
Which did improve speed by quite a bit
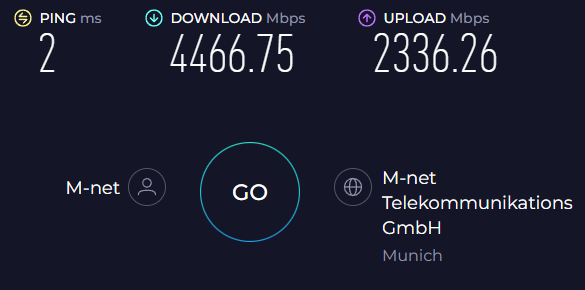
That's when I started looking at the load of my router VM ...
Receive Side Scaling
Running those Speedtests, I noticed something interesting when putting that fiber under pressure:
Tasks: 174 total, 3 running, 171 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 2.0 us, 0.0 sy, 0.0 ni, 98.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu2 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu3 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu4 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu5 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu6 : 0.0 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi,100.0 si, 0.0 st
%Cpu7 : 2.0 us, 0.0 sy, 0.0 ni, 98.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 3920.2 total, 3177.8 free, 532.6 used, 424.6 buff/cache
MiB Swap: 980.0 total, 980.0 free, 0.0 used. 3387.6 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
57 root 20 0 0 0 0 R 94.1 0.0 2:12.61 ksoftirqd/6
From this output we can see Core #6 is a bit struggling under an interrupt flood. Even more interesting, it's always CPU #6.
NICs are typically designed to distribute incoming traffic across multiple CPU cores by placing packets into different receive queues. This helps ensure that packet processing is "load-balanced" across available compute cores. A process called Receive Side Scaling (RSS).
The way how a NIC puts packets into receive queues is by using a hash function on packet data. What goes into that hash depends on the NIC's implementation, but typically it's something like Source & Destination IPs and Ports to guarantee packets for the same "flow" are processed by the same core. Summarized, the NIC has to have some protocol specific knowledge.
So why aren't my packets load-balanced across all CPU cores?
Because
- even in 2025 - we still like to use stuff like PPPoE. A protocol that adds a bit of additional overhead to our precious packets between L2 (Ethernet / VLAN) and L3 (IP) headers.
- NICs need to be smart enough / support PPPoE when using RSS and my NIC obviously doesn't
What can we do about it? A couple of solutions come to mind:
- Buy a new NIC that understands PPPoE
- Use a different PPPoE implementation (accel-ppp an implementation used in VyOS seems to be the obvious choice)
- Look into Intel's Dynamic Device Personalization (DPP) feature, which allows you to configure NICs on-the-fly
- eXpress Data Path (XDP) cpumap's
XDP Implementation
Because I am quite used to BPF and XDP, I decided to give the last option a try. In a nutshell:
- XDP allows us to process packets in the NIC's receive path, before they are passed to the kernel
- Using a
BPF_MAP_TYPE_CPUMAPandbpf_redirect_mapwe can redirect frames to different CPU cores
The following program:
- Checks if we are dealing with a VLAN-tagged PPPoE packet
- Extracts IPv4 or IPv6 source and destination addresses from a packet
- Extracts TCP or UDP source and destination ports from a packet
- Calculates a CRC32 "hash" based on this 4-tuple
- Calculates a CPU index by using a modulo on the hash and the number of CPU cores available
There are a couple of comments in the code that explain what's going on. Also I should note that NICs typically use a Toeplitz function to calculate the hash. I am abusing a simpler CRC function here, which is giving me good enough results.
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_endian.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/in.h>
#include <linux/ipv6.h>
#include <linux/tcp.h>
#include <linux/udp.h>
// Defines number of CPUs in the system. This can be set to a lower value than
// available CPUs
#define MAX_CPU 8
#define PPPOE_P_IP 0x0021
#define PPPOE_P_IPV6 0x0057
#define IP_TCP 0x06
#define IP_UDP 0x11
struct {
__uint(type, BPF_MAP_TYPE_CPUMAP);
__uint(max_entries, MAX_CPU);
__uint(key_size, sizeof(int));
__uint(value_size, sizeof(int));
} cpu_map SEC(".maps");
typedef struct vlan_hdr {
__be16 h_vlan_TCI;
__be16 h_vlan_encapsulated_proto;
} vlan_hdr;
typedef struct pppoe_hdr {
__u8 version : 4;
__u8 type : 4;
__u8 code;
__u16 session_id;
__u16 length;
__u16 protocol;
} pppoe_hdr;
typedef struct __attribute__((packed)) tuple {
__u32 saddr;
__u32 daddr;
__u16 sport;
__u16 dport;
__u8 proto;
__u16 header_len;
} tuple;
// Calculates CRC "hash" for the flow
static __always_inline __u32 crc32(const void *data, __u64 len) {
const unsigned char *p = data;
__u32 crc = 0xFFFFFFFF;
for (__u64 i = 0; i < len; i++) {
crc ^= p[i];
for (int j = 0; j < 8; j++) {
if (crc & 1)
crc = (crc >> 1) ^ 0xEDB88320;
else
crc = crc >> 1;
}
}
return ~crc;
}
// Calculates XDP data offsets and handles out of bounds check
__always_inline void *__offset(void *start, void *end, __u32 offset, __u32 len) {
void *ptr = start + offset;
if (ptr + len > end) {
return NULL;
}
return ptr;
}
// Extracts IPv4 L3 information for the hash
__always_inline int __ipv4(void *data, void *data_end, tuple *tuple) {
struct iphdr *ip;
if (ip = __offset(data, data_end, 0, sizeof(struct iphdr)), ip == NULL) {
return -1;
}
tuple->saddr = ip->saddr;
tuple->daddr = ip->daddr;
tuple->proto = ip->protocol;
tuple->header_len = ip->ihl * 4;
return 0;
}
// Extracts IPv6 L3 information for the hash, by folding v6 addresses into
// 32-bit values
__always_inline int __ipv6(void *data, void *data_end, tuple *tuple) {
struct ipv6hdr *ip;
int *saddr_ptr;
int *daddr_ptr;
if (ip = __offset(data, data_end, 0, sizeof(struct ipv6hdr)), ip == NULL) {
return -1;
}
saddr_ptr = (int *)&ip->saddr.in6_u.u6_addr32;
tuple->saddr ^= saddr_ptr[0];
tuple->saddr ^= saddr_ptr[1];
tuple->saddr ^= saddr_ptr[2];
tuple->saddr ^= saddr_ptr[3];
daddr_ptr = (int *)&ip->daddr.in6_u.u6_addr32;
tuple->daddr ^= daddr_ptr[0];
tuple->daddr ^= daddr_ptr[1];
tuple->daddr ^= daddr_ptr[2];
tuple->daddr ^= daddr_ptr[3];
tuple->header_len = sizeof(struct ipv6hdr);
tuple->proto = ip->nexthdr;
return 0;
}
// Extracts TCP L4 information for the hash
__always_inline int __tcp(void *data, void *data_end, tuple *tuple) {
struct tcphdr *tcp;
if (tcp = __offset(data, data_end, 0, sizeof(struct tcphdr)), tcp == NULL) {
return -1;
}
tuple->sport = tcp->source;
tuple->dport = tcp->dest;
return 0;
}
// Extracts UDP L4 information for the hash
__always_inline int __udp(void *data, void *data_end, tuple *tuple) {
struct udphdr *udp;
if (udp = __offset(data, data_end, 0, sizeof(struct udphdr)), udp == NULL) {
return -1;
}
tuple->sport = udp->source;
tuple->dport = udp->dest;
return 0;
}
SEC("xdp") int start(struct xdp_md *ctx) {
struct ethhdr *eth;
vlan_hdr *vlan;
pppoe_hdr *pppoe;
tuple tuple;
void *data_end;
void *data;
data = (void *)(long)ctx->data;
data_end = (void *)(long)ctx->data_end;
// Make sure tuple is all zero
__builtin_memset(&tuple, 0, sizeof(tuple));
// Get pointer to ethernet header
if (eth = __offset(data, data_end, 0, sizeof(struct ethhdr)), eth == NULL) {
return XDP_PASS;
}
// We only support VLAN-tagged packets
if (bpf_ntohs(eth->h_proto) != ETH_P_8021Q) {
return XDP_PASS;
}
// Get pointer to VLAN header
if (vlan = __offset(eth, data_end, sizeof(struct ethhdr), sizeof(vlan_hdr)), vlan == NULL) {
return XDP_PASS;
}
// We only care about PPP Session data
if (bpf_ntohs(vlan->h_vlan_encapsulated_proto) != ETH_P_PPP_SES) {
return XDP_PASS;
}
// Get pointer to PPPoE header
if (pppoe = __offset(vlan, data_end, sizeof(vlan_hdr), sizeof(pppoe_hdr)), pppoe == NULL) {
return XDP_PASS;
}
// We only support IPv4 and IPv6 packets
if (bpf_ntohs(pppoe->protocol) != PPPOE_P_IP &&
bpf_ntohs(pppoe->protocol) != PPPOE_P_IPV6) {
return XDP_PASS;
}
// Extract L3 data for the hash
switch (bpf_ntohs(pppoe->protocol)) {
case PPPOE_P_IP:
if (__ipv4((void *)pppoe + sizeof(pppoe_hdr), data_end, &tuple) < 0) {
return XDP_PASS;
}
break;
case PPPOE_P_IPV6:
if (__ipv6((void *)pppoe + sizeof(pppoe_hdr), data_end, &tuple) < 0) {
return XDP_PASS;
}
break;
}
// We only support TCP and UDP packets
if (tuple.proto != IPPROTO_TCP && tuple.proto != IPPROTO_UDP) {
return XDP_PASS;
}
void *proto_start = (void *)pppoe + sizeof(pppoe_hdr) + tuple.header_len;
switch (tuple.proto) {
case IPPROTO_TCP:
if (__tcp(proto_start, data_end, &tuple) < 0) {
return XDP_PASS;
}
break;
case IPPROTO_UDP:
if (__udp(proto_start, data_end, &tuple) < 0) {
return XDP_PASS;
}
break;
}
// Calculate CPU for the packet
__u32 cpu = crc32(&tuple, 12) % MAX_CPU;
return bpf_redirect_map(&cpu_map, cpu, 0);
}
char LICENSE[] SEC("license") = "GPL";
Let's compile this thing:
$ clang -O2 -g -target bpf -D__TARGET_ARCH_x86 -c ppp-xdp-kern.c -o ppp-xdp-kern.o
Load it into the kernel (My NIC is called enp1s0f0):
$ ip link set dev enp1s0f0 xdpdrv object ppp-xdp-kern.o sec xdp
And populate all entries in the cpumap (again 8 cores in my case). The value for each key is of type bpf_cpumap_val,
which is a 32-bit unsigned integer specifying a queue size.
$ bpftool map update name cpu_map key 0x00 0x00 0x00 0x00 value 0x00 0x40 0x00 0x00
$ bpftool map update name cpu_map key 0x01 0x00 0x00 0x00 value 0x00 0x40 0x00 0x00
$ bpftool map update name cpu_map key 0x02 0x00 0x00 0x00 value 0x00 0x40 0x00 0x00
$ bpftool map update name cpu_map key 0x03 0x00 0x00 0x00 value 0x00 0x40 0x00 0x00
$ bpftool map update name cpu_map key 0x04 0x00 0x00 0x00 value 0x00 0x40 0x00 0x00
$ bpftool map update name cpu_map key 0x05 0x00 0x00 0x00 value 0x00 0x40 0x00 0x00
$ bpftool map update name cpu_map key 0x06 0x00 0x00 0x00 value 0x00 0x40 0x00 0x00
$ bpftool map update name cpu_map key 0x07 0x00 0x00 0x00 value 0x00 0x40 0x00 0x00
Time for a final Speedtest, that shows great success.
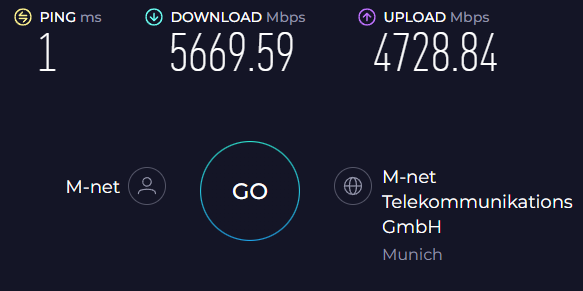
Another look at top confirms we are indeed load-balancing packets across multiple cores & the cpumap is working as
expected:
Tasks: 179 total, 1 running, 178 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.0 us, 2.0 sy, 0.0 ni, 85.7 id, 0.0 wa, 0.0 hi, 12.2 si, 0.0 st
%Cpu1 : 0.0 us, 2.0 sy, 0.0 ni, 94.0 id, 0.0 wa, 0.0 hi, 4.0 si, 0.0 st
%Cpu2 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu3 : 0.0 us, 0.0 sy, 0.0 ni, 96.1 id, 0.0 wa, 0.0 hi, 3.9 si, 0.0 st
%Cpu4 : 0.0 us, 0.0 sy, 0.0 ni, 98.0 id, 0.0 wa, 0.0 hi, 2.0 si, 0.0 st
%Cpu5 : 0.0 us, 0.0 sy, 0.0 ni, 86.0 id, 0.0 wa, 0.0 hi, 14.0 si, 0.0 st
%Cpu6 : 0.0 us, 0.0 sy, 0.0 ni, 93.8 id, 0.0 wa, 0.0 hi, 6.2 si, 0.0 st
%Cpu7 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 3920.2 total, 3159.1 free, 550.0 used, 425.8 buff/cache
MiB Swap: 980.0 total, 980.0 free, 0.0 used. 3370.2 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
46141 root 20 0 0 0 0 S 16.0 0.0 0:01.34 cpumap/0/map:300
46151 root 20 0 0 0 0 S 14.0 0.0 0:00.67 cpumap/5/map:300
46143 root 20 0 0 0 0 S 6.0 0.0 0:00.29 cpumap/1/map:300
46153 root 20 0 0 0 0 S 6.0 0.0 0:01.79 cpumap/6/map:300
46145 root 20 0 0 0 0 S 4.0 0.0 0:00.45 cpumap/2/map:300
46147 root 20 0 0 0 0 S 2.0 0.0 0:00.40 cpumap/3/map:300
46149 root 20 0 0 0 0 S 2.0 0.0 0:01.01 cpumap/4/map:300
As mentioned, there's likely more room for improvement using a proper hash function here which is a project for another weekend.
AI telephone agent using Asterisk and Cloudflare Workers AI
The idea behind AI-driven telephone agents is rather simple:
- Accept an incoming call
- Wait for some instructions
- Process instructions
- Return result to caller
I decided to build a small telephone agent with as little code as possible. Let's go through each of the steps.
Accept an incoming call using Asterisk
Instead of signing up for a new landline, I realized that my existing Internet provider (Deutsche Telekom) "gifted" me with 3 phone numbers - that I have never used. However, since they allow me to connect to the telephone network via Voice-over-IP (VoIP), this is actually a perfect fit for the project.
Asterisk - an open-source implementation of a Private Branch Exchange (PBX) - allows us to connect to a VoIP provider (using standard SIP protocols) and receive/initiate phone calls.
Configure Transport
I am using the pjsip module of Asterisk
for communications with Deutsche Telekom. And we first start by configuring how packets should be transported.
[transport-udp]
type = transport
protocol = udp
bind = 10.0.0.1
local_net = 10.0.0.0/24
This defines
- transport should happen over UDP
- the Asterisk server is running on 10.0.0.1
- local network is 10.0.0.0/24
Configure Registration
Registration is different across telco providers, but I guess some sort of authentication is required by any. Because obviously you have to "own" a specific telephone number to receive calls for it and make calls using it. DTAG uses a username & password combo.
[telekom]
type = auth
auth_type = userpass
username = <my phone number>
password = <my DTAG password>@tel.t-online.de
realm = tel.t-online.de
[telekom]
type = registration
transport = transport-udp
server_uri = sip:tel.t-online.de
client_uri = sip:+49<my phone number>@tel.t-online.de
outbound_auth = telekom
contact_user = <my phone number>
fatal_retry_interval = 20
forbidden_retry_interval = 20
retry_interval = 20
max_retries = 9999
expiration = 60
This
- tells pjsip we want to authenticate using a specific username & password
- references our transport section
- configures the server's URL (depends on telco provider)
- configures our client URL (depends on telco provider and your phone number)
- some timeouts and # of retries in case something went wrong
Configure Endpoint
Last but not least we configure an endpoint. This is kind of a sink that receives phone calls from external and internal callers.
[telekom]
type=endpoint
context=incoming
disallow=all
allow=alaw,ulaw
aors=telekom
outbound_auth=telekom
from_user=<my phone number>
from_domain=tel.t-online.de
[telekom]
type = aor
contact = sip:tel.t-online.de
[telekom]
type=identify
endpoint=telekom
match=217.0.0.0/13
This says
- whenever there's a SIP invite from 217.0.0.0/13 (address range of DTAG)
- assign it to the Telekom endpoint
- and only some specific codecs are allowed
- and whenever there's someone calling, process the Asterisk dialplan using the
incomingsection
Configure Dialplan
Now that we are registered to the provider and we are receiving a call on our phone number, the thing that decides what is happening with that call is the dialplan.
[incoming]
exten => <my phone number>,1,Verbose(1, "Incoming call with CallerID: ${CALLERID(all)}")
same => n,Answer()
exten => _.,1,Set(UUID=${SHELL(printf $(uuidgen))})
same => n,AudioSocket(${UUID},127.0.0.1:3454)
same => n,Hangup()
This is the incoming section we referenced in the endpoint. It is
- logging some information about the caller's phone number
- answers the phone
- generates a uuid using the
uuidgenprogram - opens a TCP connection to an "Audiosocket" server
The last point here is the most important bit. An Audiosocket server is a program that will receive all audio samples on a TCP socket. The TCP payload it receives is well-defined as 16-bit, 8kHz, single-channel PCM.
Wait for some instructions via a small Rust program
So, someone can call us, we accept the call and forward all audio samples to a TCP server. There are different strategies on how to extract instructions from a caller and make them processable. I decided to go with a minimalistic Voice Activity Detection (VAD) approach for this project.
We know that the Audiosocket implementation of Asterisk gives us PCM data. More specifically it gives us 8000 samples per second (8kHz). With each sample being 2 bytes (signed payload). The implementation I am using here is looking at the absolute (again, 16-bit signed payload) energy of each sample & considers every sample as speech, if that energy is above a certain threshold.
A state machine
The bigger challenge here is to extract whole instructions or sentences from a stream of samples, knowing when the caller starts and stops giving an instruction. A sneeze shouldn't be detected as speech & humans are taking a breath when giving an instruction.
I came up with a state machine that looks like this:
In case a sample's energy was above a certain threshold, the human might actually be speaking
#![allow(unused)] fn main() { fn active(&mut self, consider: f64, msec: f64) { *self = match self { VadState::Silence => VadState::Consider(msec), VadState::Consider(s) => { if *s >= consider { VadState::Speech(*s + msec) } else { VadState::Consider(*s + msec) } } VadState::Speech(s) => VadState::Speech(*s + msec), VadState::Wait(t, s) => VadState::Speech(*t + *s + msec), } } }
If
- they were silent, consider the input as speech for up to
considermilliseconds - we are currently considering the stream as speech and doing so for more than
considermilliseconds, actually mark it as speech - it was speech, we are updating the number of milliseconds the caller is talking for
There is one more transition that only makes sense when we look at the opposite case. So let's say a sample's energy is below our fixed energy threshold:
#![allow(unused)] fn main() { fn silence(&mut self, msec: f64) { *self = match self { VadState::Silence => VadState::Silence, VadState::Consider(_) => VadState::Silence, VadState::Speech(s) => VadState::Wait(*s, msec), VadState::Wait(t, s) => VadState::Wait(*t, *s + msec), } } }
If
- they were silent, do nothing
- we considered it as speech, mark it as silent (In case it isn't clear yet, the
Considerstate shall detect the "sneeze-case". If the caller Silent -> Sneeze -> Silent, we only "considered" the sneeze as speech but never really transitioned into theSpeechstate) - they were speaking, transition to a Wait state
The Wait state is important to cover the "human-took-a-breath" case. We allow the caller to go Silent -> Speak ->
Silent -> Speak,
and consider the whole sequence as a non-interrupted instruction, even though they were being silent for a little bit.
However, if the stream is in a Wait state for too long, we consider the instruction to be finished, and we'll transmit
the captured audio data to the "processor" (see next paragraph).
Additionally - and to be precise - I am not looking at the energy of individual samples. I am actually looking at a sequence of 20 samples (or 2.5 milliseconds) and use the maximum energy of those 20 samples to drive that state machine.
#![allow(unused)] fn main() { for chunk in self.chunks(20) { if chunk.energy() > ACTIVE_ENERGY { state.active(CONSIDER_MSEC, chunk.msec(self.rate)); } else { state.silence(chunk.msec(self.rate)); } } }
Process instructions using Cloudflare Workers AI
Now that we have extracted an instruction from a stream of audio samples, we can actually process it. There are many different approaches to this problem, but in a nutshell what we need to do is:
- Speech-To-Text
- Generate response
- Text-To-Speech
All of this can happen locally, or can be offloaded to some external service provider. I decided to play around with Cloudflare's Workers AI for this project.
@cf/openai/whisper-tiny-en
Takes a WAVE audio file and turns it into text. All we gotta do here is make our stream of PCM samples a WAVE PCM soundfile. Then we send this file to a Cloudflare Worker script
@cf/meta/llama-3.1-8b-instruct-fast
Within that script we are piping the text to a generative text model to generate a response
@cf/myshell-ai/melotts
I also don't want to deal with generating audio from that response myself, so I am using a third model that takes the response as text and provides me with some audio.
Return result to caller
After receiving the response audio from the Cloudflare Workers AI endpoint, we have to transform it to an audio format that Asterisk's Audiosocket understand. Workers AI gives us an mp3, but we need a 8kHz, 16-bit, single-channel PCM stream.
While there are other options my simple approach here is to call into ffmpeg to do the heavy lifting for me:
#![allow(unused)] fn main() { let mut child = Command::new("ffmpeg") .arg("-i") .arg("pipe:0") .arg("-f") .arg("s16le") .arg("-ac") .arg("1") .arg("-acodec") .arg("pcm_s16le") .arg("-ar") .arg("8000") .arg("pipe:1") .stdin(Stdio::piped()) .stderr(Stdio::piped()) .stdout(Stdio::piped()) .spawn() .unwrap(); }
This
- pipes the mp3 from Cloudflare into ffmpeg
- converts the data to raw PCM
- pipes the PCM audio data to my program
The resulting PCM audio samples can now be sent over the existing Audiosocket TCP connection and the caller will receive the generated reply. It's important to not send the whole audio to Asterisk in one go but rather chunk it and send chunks at the same pace as we are receiving samples from Asterisk.
The Audiosocket server as well as the Cloudflare Worker can be found on Github
STM32F439 openocd ITM Debugger
Experimenting with a Cortex-M4 on a Nucleo Board, goal is to get printf-style debugging to work.
This microcontroller has as Instrumentation Trace Macrocell Unit (ITM), that allows for writing printf-style debug messages to "stimulus registers". Those messages then flow through a Trace Port Interface Unit (TPIU), which outputs data to a Serial Wire Output (SWO), which can then be collected using openocd

Clocks
The development board has a couple of different clocks that can drive SYSCLK. I had some pretty inconsistent results - likely due to clock drifts / temperature - using the on-board 16 MHz High-Speed Internal (HSI) oscillator. There's an 8 MHz High-Speed External (HSE) clock source available which is sourced from the on-board STLink that was working better for me.
Enable HSE using RCC_RC
RCC Clock Control Register (RCC_CR) allows us to enable HSE. We also need to wait until it's ready.
#![allow(unused)] fn main() { RCC_CR.set(RCC_CR_HSEON); while RCC_CR.get(RCC_CR_HSERDY) == 0 {} }
Feed HSE into SYSCLK
RCC Clock Configuration Register (RCC_CFGR) is used to feed the system clock with HSE.
#![allow(unused)] fn main() { RCC_CFGR.set_from(RCC_CFGR_SW, 1); while RCC_CFGR.get(RCC_CFGR_SWS) != 1 {} }
Disable HSI
HSI is useless from now on so we can disable.
#![allow(unused)] fn main() { RCC_CR.clear(RCC_CR_HSION); while RCC_CR.get(RCC_CR_HSIRDY) != 0 {} }
Configure ITM / TPIU
38.14.2 of the board's reference manual goes into great detail how the ITM need to be configured:
- Configure the TPIU and assign TRACE I/Os by configuring the DBGMCU_CR (refer to Section 38.17.2 and Section 38.16.3)
- Write
0xC5ACCE55to the ITM Lock Access register to unlock the write access to the ITM registers - Write
0x00010005to the ITM Trace Control register to enable the ITM with Sync enabled and an ATB ID different from 0x00 - Write
0x1to the ITM Trace Enable register to enable the Stimulus Port 0 - Write
0x1to the ITM Trace Privilege register to unmask stimulus ports 7:0 - Write the value to output in the Stimulus Port register 0: this can be done by software (using a printf function)
#![allow(unused)] fn main() { DBGMCU_CR.set(DBGMCU_CR_TRACE_IOEN); DBGMCU_CR.clear(DBGMCU_CR_TRACE_MODE); ITM_LOCK_ACCESS.write(0xC5AC_CE55u32); ITM_TRACE_CONTROL.write(0x0001_0005u32); ITM_TRACE_ENABLE.set(ITM_TRACE_ENABLE_PORT0); ITM_TRACE_PRIVILEGE.set(ITM_TRACE_PRIVILEGE_PORT0_7); }
However, I have reasons to believe that all of this is being handled by openocd, which we'll use next.
Write to Stimulus Port
We can write ASCII bytes to the ITM with something like this:
#![allow(unused)] fn main() { ITM_STIMULUS_PORT_0.write(character as u8); }
And before each write, we need to make sure that the stimulus port can accept writes
#![allow(unused)] fn main() { while ! ITM_STIMULUS_PORT_0.all_set(BIT0) {} }
Bake Binary
I am using rust to compile my programs
$ cargo build --release
And objcopy to make the ELF a real binary
$ aarch64-unknown-linux-gnu-objcopy \
-O binary \
target/thumbv7em-none-eabihf/release/main \
target/thumbv7em-none-eabihf/release/flash
And openocd to bake that image into the microcontroller's flash memory
$ openocd \
-f /usr/share/openocd/scripts/board/st_nucleo_f4.cfg \
-c "init; reset halt; flash write_image erase target/thumbv7em-none-eabihf/release/flash 0x08000000 bin; reset run; exit"
Running openocd
Finally we can run openocd, attach to the board and print message we wrote to the ITM to stdout. It's important to match traceclk with SYSCLK, which was 8 MHz in my case.
$ openocd \
-f /usr/share/openocd/scripts/board/st_nucleo_f4.cfg \
-c "init; stm32f4x.tpiu configure -protocol uart -traceclk 8000000 -output /dev/stdout -formatter 0; itm ports on; stm32f4x.tpiu enable"
Open On-Chip Debugger 0.12.0
Licensed under GNU GPL v2
For bug reports, read
http://openocd.org/doc/doxygen/bugs.html
Info : The selected transport took over low-level target control. The results might differ compared to plain JTAG/SWD
srst_only separate srst_nogate srst_open_drain connect_deassert_srst
Info : clock speed 2000 kHz
Info : STLINK V2J39M27 (API v2) VID:PID 0483:374B
Info : Target voltage: 3.227694
Info : [stm32f4x.cpu] Cortex-M4 r0p1 processor detected
Info : [stm32f4x.cpu] target has 6 breakpoints, 4 watchpoints
Info : starting gdb server for stm32f4x.cpu on 3333
Info : Listening on port 3333 for gdb connections
Info : SWO pin data rate adjusted by adapter to 2000000 Hz
Info : Unable to match requested speed 2000 kHz, using 1800 kHz
Info : Unable to match requested speed 2000 kHz, using 1800 kHz
[stm32f4x.cpu] halted due to debug-request, current mode: Thread
xPSR: 0x01000000 pc: 0x080001b4 msp: 0x20020000
Info : Listening on port 6666 for tcl connections
Info : Listening on port 4444 for telnet connections
Hello World